For most of 2023 through 2025, the conversation around conversational AI was about chatbots: glorified FAQ widgets that could string together a paragraph and look smart doing it. By 2026, that framing feels quaint. The interesting question is no longer "can the bot answer?" - it is "can the agent finish the job?"
That shift is what people mean when they say "AI agent." A chatbot replies. An agent decides, calls tools, updates systems, and stops only when the goal is met. The reason this is suddenly viable in production - not just in demos - is that the underlying models grew up. Claude Opus 4.7 leads SWE-bench Pro at 64.3% and is the most reliable tool-caller we ship on. Moonshot's Kimi K2.6 can run twelve-hour autonomous coding sessions and orchestrate up to 300 sub-agents across 4,000 coordinated steps. GLM-5.1 from Z.ai runs an eight-hour plan-execute-test-fix loop under an MIT license. DeepSeek V4 Flash runs at $0.14 per million input tokens with a 1M-token context window. Gemini 3.1 Ultra holds 2M tokens and reads text, image, audio, and video natively. The combination - strong tool use, very long context, and per-resolution costs measured in fractions of a cent - is what turns "agent" from a buzzword into a budget line.
So if you have been hearing the noise but are not sure where to actually point an agent in your business, this is the practical version. Eight use cases we see Berrydesk customers ship most often, what each one looks like in real traffic, and the model and trade-off choices that make them work.
1. Upsell and cross-sell that actually reads the basket
The dirty secret of most upsell modules is that they are based on three rules and a hardcoded shelf. "If user buys A, suggest B." It works, narrowly. What it cannot do is read the conversation. A returning customer asking your support widget about replacement filters for a coffee machine is not the same shopper as someone asking how to descale it for the first time, even though both will end up on the same product page.
An AI agent on the chat surface treats each conversation as its own context. With Berrydesk you can give the agent your product catalog, the shopper's order history, and the live cart, and let it propose the next item in a way that fits what the person is actually trying to do. A customer dropping running shoes into the cart gets a sock and water-bottle bundle priced for their tier. A B2B buyer reordering a SKU they bought last quarter gets nudged about the volume discount they just barely missed. The agent does not just say "you might also like" - it explains why, in one sentence, in the brand's voice.
Routing matters here. Upsell flows are high volume and price-sensitive, so most teams point them at a fast, cheap model - DeepSeek V4 Flash or MiniMax M2 - and only escalate to Claude Opus 4.7 when the basket is large or the conversation gets unusual. That mix lets you run thousands of nudges a day for a few dollars rather than a few hundred.
2. Order and shipment status without the email scavenger hunt
"Where is my package?" is the single most common ticket in e-commerce support. It is also the easiest one to take off the queue entirely.
An agent connected to your order management system handles this end to end. Customer asks; the agent looks up the order, pulls the carrier's latest scan, returns the ETA, and offers the next legitimate step - reschedule, redirect to a pickup point, file a missing-package claim. If the package is genuinely lost, it can open the claim ticket, attach the order context, and hand the conversation off to a human with everything pre-filled.
The technical bar here is not language - every model since GPT-4 could write a polite shipping update. The bar is reliable tool-use against your real backend. That is where the new generation of agentic models earns its keep: Claude Opus 4.7, Kimi K2.6, and Qwen3.6 all chain multiple API calls without going off-script, which is the difference between an agent that tells the customer "your package is delayed" and one that also detects the address typo, refunds the expedited shipping fee, and reships from the closer warehouse.
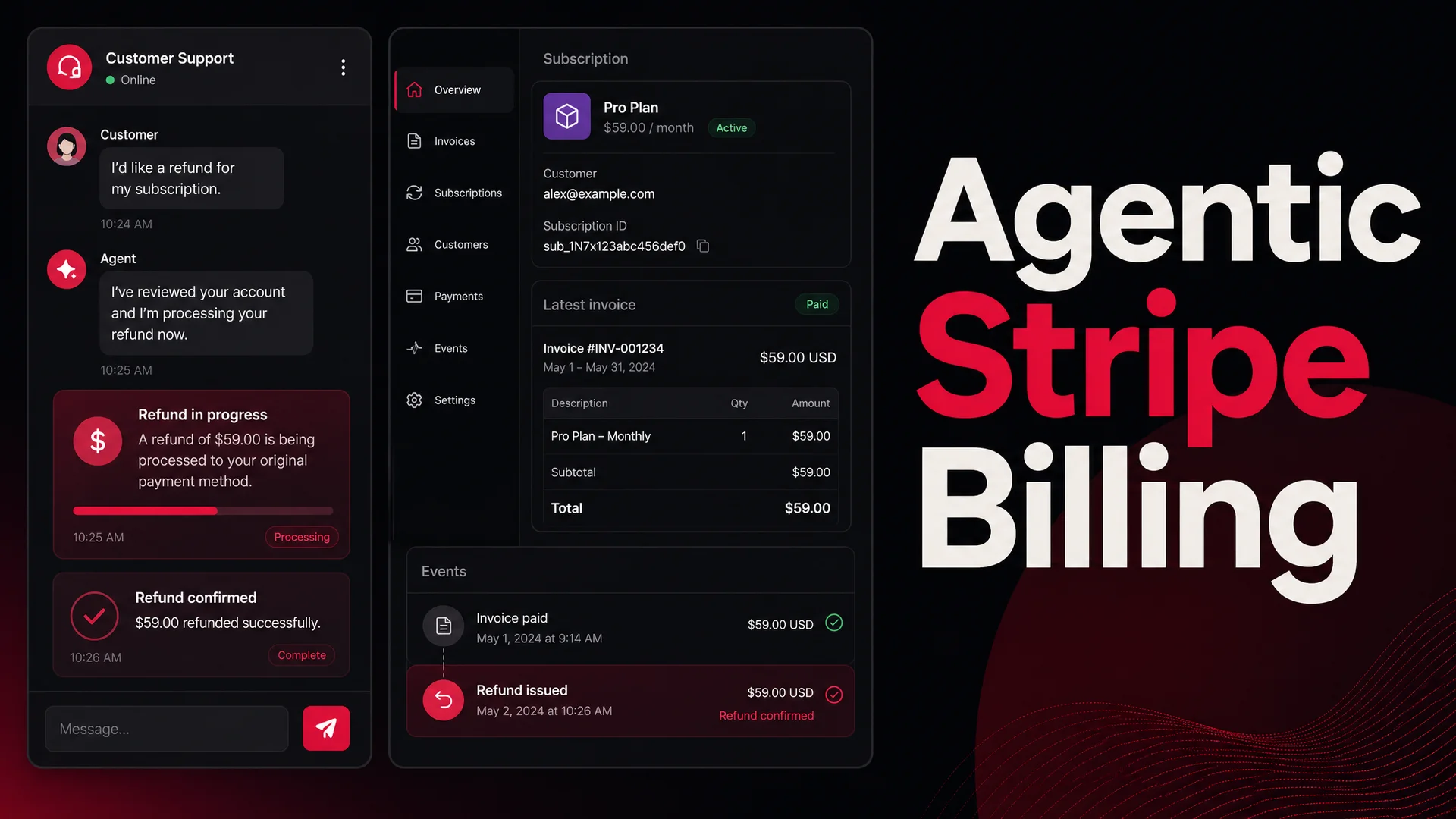
3. Billing questions that get resolved in the chat, not the queue
Billing is where customer patience evaporates fastest. Charges they do not recognize, invoices that mismatch the contract, prorated upgrades that look wrong on first read - these conversations stretch into days when they bounce between the customer, support, and finance.
An agent with read access to your billing system, plus a tightly scoped set of AI Actions for refunds and credits, collapses that loop. The customer asks about a charge; the agent retrieves the invoice line items, walks through them in plain language, and - if the charge is wrong - issues the credit on the spot under whatever rules you set ("up to $50 with no human review, anything larger goes to a finance approver").
The guardrails are the interesting part. Berrydesk lets you set per-action limits, require structured confirmations, and log every executed action with the reasoning trace, so a finance lead can audit any decision the agent made. That is what makes it safe to give an LLM the keys to refund money. If you cannot explain what the agent did and why, you should not be running it on billing flows yet.
4. Personalized recommendations that are not just "people also bought"
Generic recommendation widgets are statistical: they tell you what other people did. A real personalization agent is conversational: it asks. The difference shows up most clearly in categories where preference is hard to infer from clicks - fitness, beauty, B2B software, anything where the buyer has constraints that do not map cleanly onto SKU metadata.
A Berrydesk agent can run a short, friendly intake - three or four questions tuned to the category - and use the answers, plus past behavior, to narrow the catalog. A shopper looking for a running watch gets asked about distance, terrain, and whether they care about heart-rate accuracy more than battery life. The agent then surfaces the two or three watches that actually fit, with a one-line rationale per pick.
This is also where 1M-token context windows pay off. You can feed the entire product catalog, the brand voice guide, and the customer's full history into a single prompt without the brittleness of building a retrieval pipeline for it. RAG still helps when catalogs run into millions of SKUs, but for the long tail of mid-sized commerce shops, long context turns recommendations from an engineering project into a configuration step.
5. Subscription management with no support handoff
Pause my plan. Switch from monthly to annual. Add a seat. Move my renewal date. These are some of the highest-volume support requests for any subscription business, and almost none of them require a human.
An agent backed by your billing and entitlement APIs handles the whole exchange in chat: confirms identity, checks for any constraints (open invoices, contract terms), executes the change, and follows up with a confirmation summary. If the request is out of policy - a request to refund the unused portion of an annual plan, say - the agent surfaces the rule, offers the alternatives that are in policy, and only escalates if the customer asks for an exception.
The result is the same dynamic as billing: you stop measuring this category of ticket in resolution time and start measuring it in deflection. Berrydesk customers running this flow regularly see 60–80% of subscription requests resolved in the agent without ever entering the human queue.
6. Real customer support tasks, not just answers
This is where the line between "chatbot" and "agent" gets sharp. A chatbot can tell a customer how to reset their password. An agent resets it.
For a SaaS product that means the agent can verify identity, change an email address, toggle a feature flag for that account, generate an API key, walk through a SSO setup with the right tenant ID, or check why a webhook is failing and fix the misconfigured URL. Each of these is a small thing on its own, but together they are the substrate of a support team's daily work - and every one of them follows a procedure that can be encoded as an AI Action.
The reason this is reliable in 2026 and was not in 2024 is the maturity of agentic tool-use. Kimi K2.6's 4,000-step coordinated chains, GLM-5.1's eight-hour autonomous loop, and Claude Opus 4.7's tool-use accuracy are the difference between an agent that hallucinates an API call and one that runs a five-step troubleshooting flow without a misstep. With Berrydesk you wire the agent to your internal APIs, define each action with a JSON schema and a permissions scope, and let the model pick the right tool for the request.
A practical pattern: keep a "human-in-the-loop" mode on any action that mutates production data for the first month, see what the agent actually does, and progressively widen its autonomy as you build trust in specific action types. Every Berrydesk customer who skipped this step regretted it.
7. Lead capture that feels like a conversation
Static forms convert because the alternative is nothing, not because they are good. A two-question chat with a real model captures higher intent and gives sales something to work with on the first call.
A Berrydesk agent placed on a marketing site opens with an actual question - "what brought you here?" - and shapes the rest of the exchange around the answer. By the time the visitor has typed three or four messages, the agent has pulled out their company size, their use case, what they already tried, and what is blocking them. That payload lands in your CRM with the lead's email address and a clean summary, not just a name and a textarea full of "looking for help."
The trick is not making it feel like an interrogation. The model needs to be tuned for a light, conversational tone - small models like DeepSeek V4 Flash or Qwen3.6-27B do this well at low cost - and the conversation needs natural exit ramps for visitors who do not want to chat. A "skip to a form" link buys you the visitors the agent loses.
8. Lead qualification, scoring, and routing in one pass
Lead capture and lead qualification get treated as separate stages in most teams' funnels because the tools were separate: a form for capture, a sales rep for qualification. An agent collapses them.
Inside the same conversation, the agent runs the BANT-style questions you would otherwise leave to an SDR - budget, timeline, authority, the specific problem they are solving - and produces a structured output: a lead record with a score, a category (hot/warm/cold or whatever schema you use), and a recommended next action. That record gets pushed into HubSpot, Salesforce, or Notion via Berrydesk's AI Actions, and a Slack ping goes to the rep who owns the territory.
For high-intent leads - a clearly qualified buyer, a recognized account from a target list - the agent can go a step further and book the demo directly into the rep's calendar. The customer leaves the conversation with a meeting on their calendar instead of "someone will reach out within 24 hours," which historically meant 36 hours and a cold opener.
What changed in 2026 that makes this different
A short detour, because this is the part that decides whether any of the above ships in your stack or stays a slide deck.
Cost stopped being the bottleneck. Routine support traffic on DeepSeek V4 Flash or MiniMax M2 runs at fractions of a cent per resolution. You can route 95% of conversations through a small open-weight model and reserve Claude Opus 4.7, GPT-5.5, or Gemini 3.1 Ultra for the long-tail escalations where reasoning quality matters. Berrydesk does that routing for you under the hood.
Context windows stopped being the bottleneck. With 1M-to-2M-token context windows on Claude, Gemini, DeepSeek, and Kimi, you can hold an entire knowledge base, the full conversation history, and the customer's record in a single prompt. RAG remains useful for very large catalogs and for citation, but for most support workloads it has moved from a hard requirement to a tuning lever.
Tool-use stopped being unreliable. This is the biggest one. The agentic models - Claude Opus 4.7, Kimi K2.6, GLM-5.1, Qwen3.6, MiMo-V2-Pro - get the right tool, with the right arguments, on the first try far more often than the previous generation. That is what lets AI Actions go to production.
Open-weight options unlocked regulated industries. GLM-5.1 (MIT), Qwen3.6-27B (Apache 2.0), and the MiMo-V2 family (MIT) make on-prem and air-gapped deploys realistic for healthcare, finance, and government workloads where sending data to a US frontier provider is not on the table.
Common pitfalls when you actually go to ship
A few things that consistently bite teams the first time they try this:
- Treating the agent as one big prompt. It isn't. It is a router, a small set of well-scoped tools, a knowledge source, and a fallback. Each of those is a separate design choice. Keep them separate in your head and in your config.
- Skipping the human-in-the-loop period. You will be surprised by what the model decides to do with edge cases. Watch it for two weeks before you give it autonomy on high-stakes actions.
- Not logging the reasoning trace. When something goes wrong - and something will - you want to see why the agent did what it did, not just what it did. Berrydesk surfaces the full trace by default; some other platforms do not.
- Choosing the model before the workload. Not every task needs Claude Opus 4.7. Most do not. Build the workflow first, then pick the cheapest model that hits your quality bar for that specific step.
- Confusing demo quality with production quality. A flow that works on five hand-picked examples may break on the sixth real customer. Test on a sample of your actual ticket history, not a synthetic script.
Where to start
If you are new to this, do not try to ship all eight at once. Pick the use case where you can measure the result most cleanly - usually order tracking or billing - and ship that one well. Once you have a month of real data and one round of model tuning behind you, the second use case is much easier than the first.
Berrydesk lets you spin up a branded AI agent in four steps: pick the model that fits the workload, train it on your docs, websites, Notion, Drive, and YouTube content, brand the chat widget, and wire up the AI Actions you need. Deploy to your website, Slack, Discord, WhatsApp, or wherever your customers actually are. The free tier is enough to ship the first use case end-to-end - start there and see what your traffic actually looks like before you commit to anything bigger.
Ship a real AI agent, not a demo
- Pick from GPT-5.5, Claude Opus 4.7, Gemini 3.1, DeepSeek V4, Kimi K2.6, GLM-5.1 and more
- Add AI Actions for bookings, refunds, and order lookups in minutes
Set up in minutes

Chirag Asarpota is the founder of Strawberry Labs, the team behind Berrydesk - the AI agent platform that helps businesses deploy intelligent customer support, sales and operations agents across web, WhatsApp, Slack, Instagram, Discord and more. Chirag writes about agentic AI, frontier model selection, retrieval and 1M-token context strategy, AI Actions, and the engineering it takes to ship production-grade conversational AI that customers actually trust.