
Qwen3-TTS is a free, open-source voice model that clones a voice from about 3 seconds of audio, designs new voices from a written description, and speaks 10 languages. Here are the links to try it and run it yourself, followed by everything you need to actually use it.
The links
Just want to try it fast? Use the free online demos - nothing to install, runs in your browser:
- Clone a voice - Qwen TTS Clone Demo
- Design a new voice from a description - Qwen3-TTS Voice Design
Want it free and private on your own computer? Set it up through Hugging Face and GitHub - the models are open and run locally:
- Code, install steps, and examples - github.com/QwenLM/Qwen3-TTS
- Download the models - huggingface.co/Qwen
Everything below explains what each option is, how to use it, and where Qwen3-TTS stands against ElevenLabs.
What Qwen3-TTS actually is
Qwen3-TTS is an open-source text-to-speech model from the Qwen team at Alibaba Cloud, released under the Apache 2.0 license. That license is the whole story: you can download the weights, run them on your own hardware, ship them inside a commercial product, and never pay a per-character fee. There is no usage meter and no monthly seat.
For anyone who has watched an ElevenLabs bill climb with every minute of generated audio, that is the headline. But "free" only matters if the quality is there, and this is where Qwen3-TTS stops being just another open model. It does three things that used to be the reason people paid:
- Clones a voice from about 3 seconds of audio. Feed it a short reference clip and it generates new speech in that voice.
- Designs brand-new voices from a written description. Describe the tone, mood, age, and personality in plain language and it builds a voice to match - no reference audio at all.
- Speaks 10 languages and ships with a set of ready-to-go preset voices, so you can start generating before you record anything.
It is genuinely multilingual: Chinese, English, German, Italian, Portuguese, Spanish, Japanese, Korean, French, and Russian. A cloned voice carries across those languages, so a 3-second English sample can speak Japanese in the same timbre.
The three things it does
1. Voice cloning from 3 seconds
This is the feature that turns heads. Most cloning tools want a minute or more of clean audio. Qwen3-TTS works from roughly a 3-second sample. Drop in a clip - your own voice, a permitted recording, a character read - and it produces new lines that match the timbre, not just a generic "male" or "female" preset.
The catch worth stating plainly: 3 seconds gets you a convincing clone, but a longer, cleaner reference still produces a more faithful one. Garbage in, garbage out applies. A crisp 10-second sample beats a noisy 3-second one.
2. Voice design from a text description
Voice cloning needs a source. Voice design needs nothing but words. You write something like "a calm middle-aged male announcer with a deep, magnetic voice and a steady, unhurried pace" and the model invents a voice that fits - controlling timbre, emotion, prosody, and persona from the instruction alone.
This is the part that quietly replaces a lot of paid stock-voice catalogs. Instead of scrolling a library hoping one of 50 voices is close enough, you describe the exact voice the project needs and generate it. Want it warmer? More tired? A faster delivery for an ad read? Rewrite the description and try again - the iteration loop is a sentence, not a new recording session.
3. Built-in voices, ready to go
If you don't want to clone or design anything, the CustomVoice models ship with nine preset speakers - Vivian, Serena, Uncle_Fu, Dylan, Eric, Ryan, Aiden, Ono_Anna, and Sohee - so you can generate usable audio the moment it's installed.
Try it in your browser in 60 seconds
The fastest path is the hosted demo - no GPU, no Python, no install:
- Open the clone demo or the voice design demo.
- For cloning, upload or record a short reference clip. For design, type a description of the voice you want.
- Type the text you want spoken, pick the language, and generate.
- Listen, tweak the reference or the description, and regenerate until it lands.
These are free Hugging Face Spaces, so they can get busy and queue at peak times. If a Space is slow, that's the trade-off for free hosted compute - which is exactly why the local setup below exists.
Run it free and private on your computer
Hosting it yourself is the version that matters most: free forever, fully private, and no clip ever leaves your machine. Here's the shape of it.
Pick a model. Qwen3-TTS ships in a few flavors so you can trade quality for speed:
| Model | Size | Best for |
|---|---|---|
| Qwen3-TTS-12Hz-1.7B-VoiceDesign | 1.7B | Designing voices from text descriptions |
| Qwen3-TTS-12Hz-1.7B-CustomVoice | 1.7B | Highest-quality preset and cloned voices |
| Qwen3-TTS-12Hz-0.6B-CustomVoice | 0.6B | Speed-sensitive or lighter-hardware setups |
| Qwen3-TTS-12Hz-*-Base | 0.6B / 1.7B | Building on top of the base model |
The 1.7B models produce the best quality; the 0.6B models are the move when you care about latency or you're on a modest GPU. It runs on consumer hardware - the smaller model is reported to fit in roughly the 4 GB VRAM range - and supports both streaming and non-streaming generation, so you can pipe audio out as it's produced for real-time use.
Install and run. The GitHub repo has the current steps. At a high level:
- Install the
qwen-ttsPython package (the Transformers-based path) and pull the model weights from Hugging Face. - Load a model, pass it your text plus either a reference clip (clone), a voice description (design), or a preset name.
- For serving at scale, vLLM has day-0 support, which gets you faster throughput than the plain Transformers path.
Don't want to self-host at all? Alibaba Cloud's DashScope offers a hosted real-time API for the cloning, design, and CustomVoice models. You give up the "fully private" part, but you skip the GPU - a middle ground between the free demo and running your own box.
How it works under the hood
If you like knowing what you're running, this is the architecture in one picture.
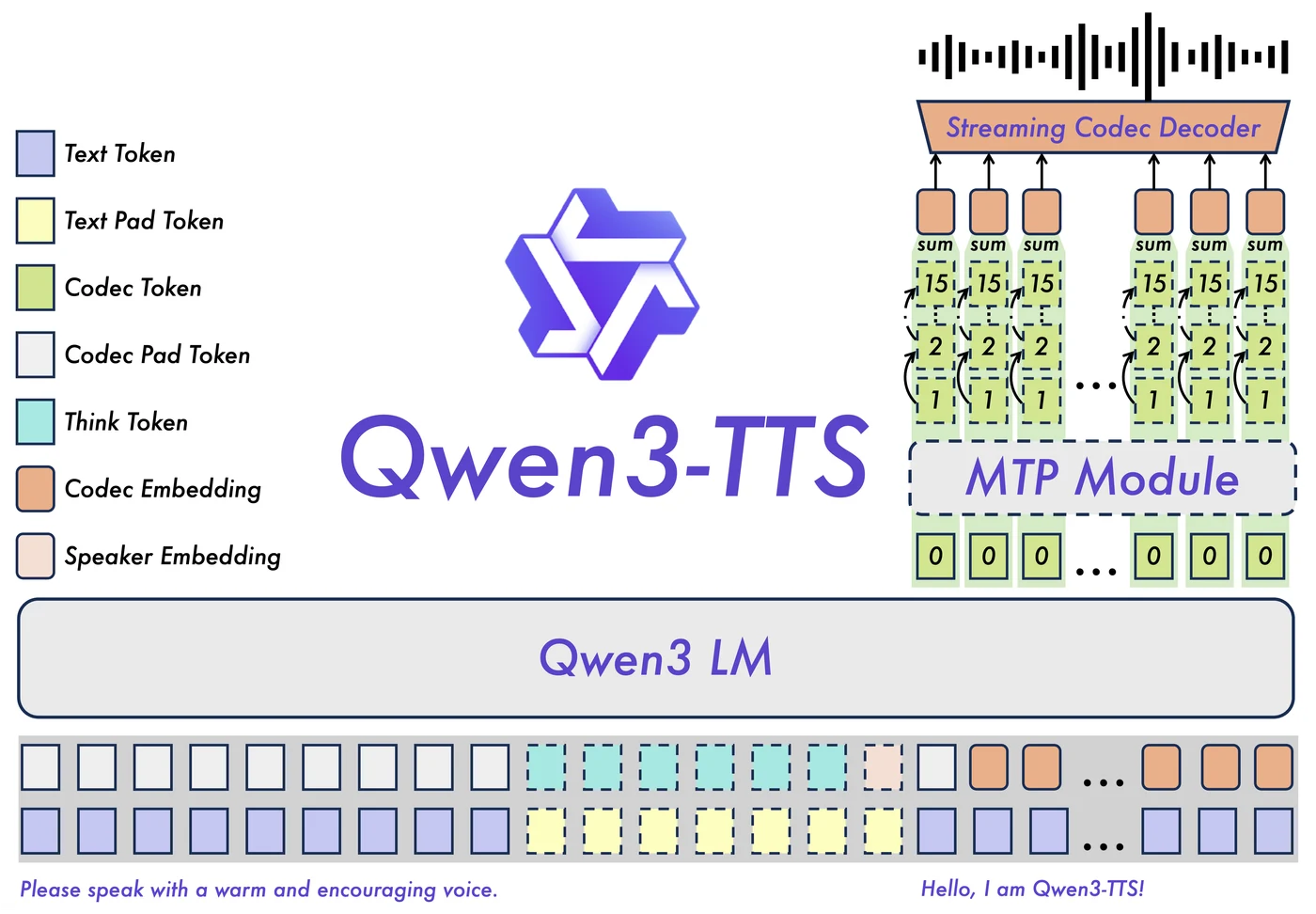
The base is a Qwen3 language model - the same family that powers Qwen's chat models. It treats speech as a sequence of tokens: text tokens go in alongside a speaker embedding and an optional voice-design instruction, and the model predicts codec tokens (a compressed representation of audio) rather than words. An MTP (multi-token prediction) module helps it generate those audio tokens efficiently, and a streaming codec decoder turns them into the actual waveform you hear, in real time.
The practical upshot: because it's built on a strong language model, it understands the text it's speaking - phrasing, emphasis, and the emotion implied by a voice-design instruction - rather than just stitching phonemes together. That's why the prosody sounds intentional instead of robotic.
Qwen3-TTS vs ElevenLabs: the honest version
You'll see Qwen3-TTS billed as cloning voices better than ElevenLabs. Qwen's own benchmarks put it at or near state-of-the-art, and several independent reviews rate the cloning as comparable or better. But "better" depends on your audio, your language, and your ear, so here's the fair comparison rather than the hype version.
| Qwen3-TTS | ElevenLabs | |
|---|---|---|
| Cost | Free, self-hosted (Apache 2.0) | Per-character / credit pricing |
| Privacy | Fully local - audio never leaves your machine | Cloud only |
| Voice cloning | ~3 seconds of reference audio | Short samples; instant + pro cloning |
| Voice design from text | Yes | Yes (Voice Design) |
| Languages | 10 | 30+ |
| Run offline | Yes | No |
| Commercial use | Allowed under the license | Allowed on paid plans |
| Ecosystem / polish | Newer, more DIY | Mature dubbing, API, integrations |
Where ElevenLabs still wins: breadth of languages, a more polished product, dubbing and project tooling, and zero setup. If you need 25 languages tomorrow or you never want to touch a GPU, it earns its price.
Where Qwen3-TTS wins, and why it's a real threat: cost goes to zero, your data stays on your hardware, and the quality is close enough that for a large share of use cases the paid bill stops making sense. For a developer building voice into a product, "free, private, and good enough" beats "excellent and metered" more often than ElevenLabs would like.
The honest recommendation: don't take anyone's benchmark on faith. Open the clone demo, feed it the exact voice and language you care about, and judge it on your own audio. That test takes two minutes and settles the argument better than any chart.
Is it really free? The license and the ethics
Yes - Apache 2.0 means free to use, modify, and ship commercially, with no per-character fee when you self-host. The only paid path is the optional hosted DashScope API, and that's usage-based cloud compute, not a license cost.
The line that actually matters isn't legal, it's consent. Cloning a voice from 3 seconds is powerful, and that cuts both ways. Clone your own voice, voices you have explicit permission to use, or voices that are clearly licensed for it. Cloning a real person without their consent - to impersonate, deceive, or scam - is the kind of thing that gets technology like this regulated, and it's wrong regardless of what the license permits. Use it on voices you have the right to use.
FAQ
Is Qwen3-TTS free? Yes, under Apache 2.0. Self-hosting costs nothing beyond your own compute. The hosted API is the only paid option, and it's optional.
How much audio do I need to clone a voice? About 3 seconds works. A longer, cleaner reference produces a more faithful clone.
What languages does it support? Ten: Chinese, English, German, Italian, Portuguese, Spanish, Japanese, Korean, French, and Russian.
Do I need a GPU? For the local version, a consumer GPU is the comfortable path, and the 0.6B model is the lighter option. No GPU? Use the free browser demo or the hosted API instead.
Can I use cloned voices commercially? The license allows commercial use. The constraint is consent - only clone voices you have the right to clone.
Is it actually better than ElevenLabs? On Qwen's benchmarks and several reviews, the cloning is comparable or better, but it trails on language count and product polish. Test it on your own audio before you decide.
Where this fits
Open voice models crossing the "good enough" line is part of a bigger shift: the expensive, metered building blocks of AI products are turning into free, ownable components. Voice was one of the last holdouts, and Qwen3-TTS is a strong sign that's ending too.
For a lot of people, the move is simple - run the demo, clone a voice, and stop paying for something you can now host yourself. For anyone building a product on top of these models, the harder part was never the speech; it's wiring a model into something that actually answers customers, takes actions, and stays reliable. That's the gap worth spending your time on.
Sources: the Qwen team's Qwen3-TTS announcement and GitHub repository, the official Hugging Face Spaces and model pages, and independent reviews. Qwen ships updates frequently - verify model names, install steps, and VRAM requirements against the official repo before relying on them.
Turn open models like this into a real customer-facing agent
- Deploy AI agents that handle support, sales, and ops across web, WhatsApp, Slack, Instagram, and Discord.
- Pick the best model for each job - voice, chat, retrieval - without writing the glue code or babysitting infrastructure.
Set up in minutes

Chirag Asarpota is the founder of Strawberry Labs, the team behind Berrydesk - the AI agent platform that helps businesses deploy intelligent customer support, sales and operations agents across web, WhatsApp, Slack, Instagram, Discord and more. Chirag writes about agentic AI, frontier model selection, retrieval and 1M-token context strategy, AI Actions, and the engineering it takes to ship production-grade conversational AI that customers actually trust.


