The phrase "AI agent" got cheap fast. By the time you read this, your inbox probably has at least three vendors claiming to sell you one. The actual engineering question - how to build a system that perceives a request, reasons about it, decides which tools to call, executes those calls reliably, and recovers when something goes wrong - is harder than the marketing suggests, and the toolkit available in May 2026 looks nothing like the toolkit of even 18 months ago.
This guide is the working version of how we think about agent development at Berrydesk, where companies use our platform to launch branded support agents that book meetings, process refunds, look up orders, and resolve tickets across web, Slack, Discord, and WhatsApp. Whether you build from scratch with the SDKs below or assemble an agent in our four-step builder, the mental model is the same. The difference is mostly how many weekends you want to spend writing retry logic.
What an AI agent actually is in 2026
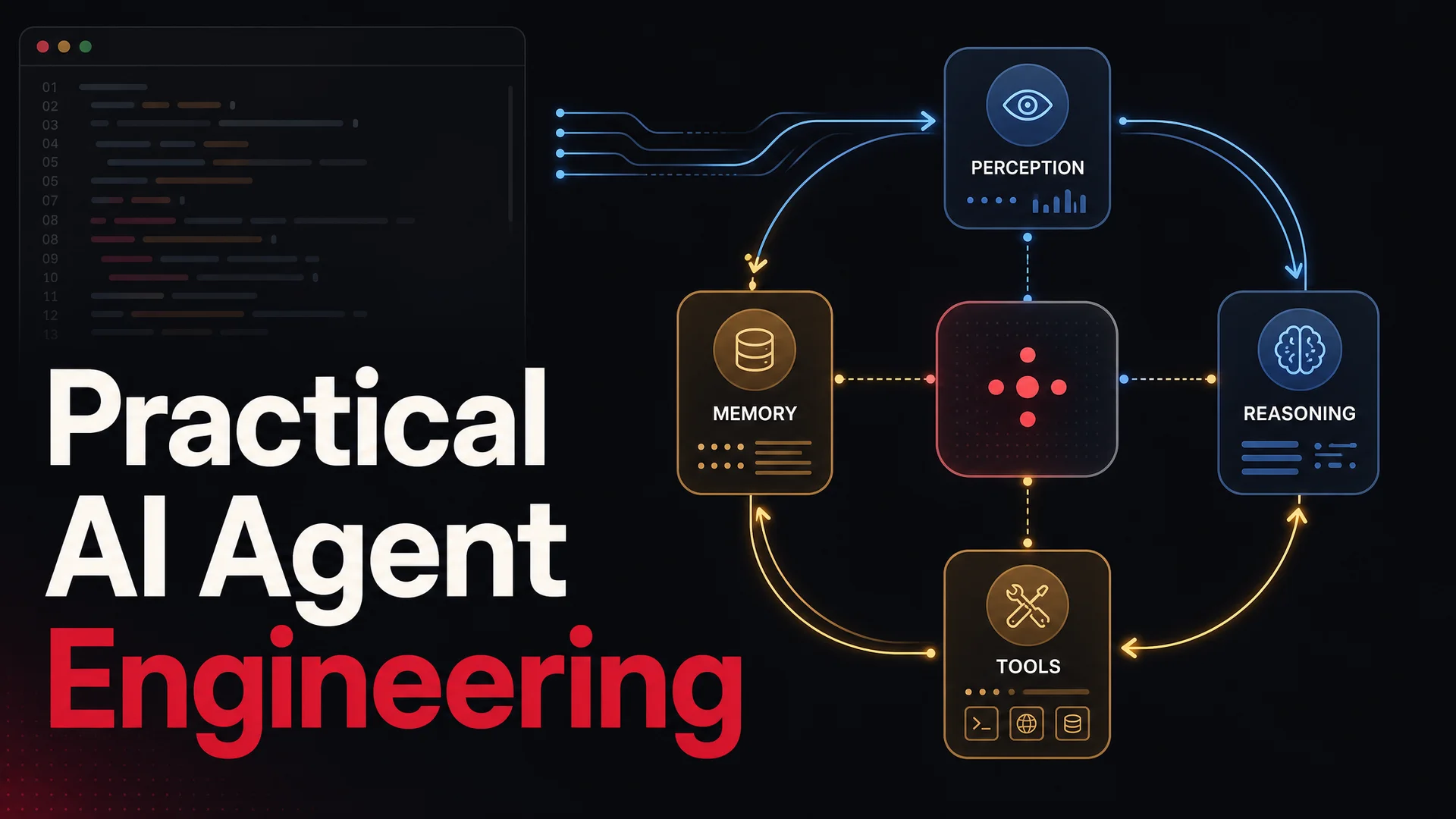
An AI agent is a software loop that takes an input, plans a response, executes that plan against tools or APIs, observes the results, and either finishes or iterates. The loop part is the important word. A model that answers a question in one shot is a chatbot. A system that decides on its own that it needs to look up an order, then call a refund API, then send a confirmation email, is an agent.
Three pieces make the loop work:
- Perception. The agent ingests the user's message plus any structured context - a chat history, a knowledge base, a customer record, a webhook payload. In 2026 this often includes images, PDFs, audio clips, and even short video, since frontier models are natively multimodal.
- Reasoning. A large language model decides what to do next. This is where "agentic" tuning matters. Models like Claude Opus 4.7, Kimi K2.6, GLM-5.1, Qwen3.6, and Xiaomi MiMo-V2-Pro are trained specifically to plan multi-step tool calls and recover from failure rather than just produce eloquent prose.
- Action. The agent invokes external tools - a search API, a CRM, a payment gateway, a database - through a structured tool-use interface, then feeds results back into the model for the next reasoning step.
The traditional taxonomy you may have seen in older textbooks - reactive, limited-memory, theory-of-mind, self-aware - is still useful pedagogy, but it does not map cleanly to what production systems actually look like. A real-world support agent is a limited-memory system with explicit short-term context (the conversation), structured long-term memory (a vector store or database), an arsenal of tools, and a planner that decides which to use. That is the shape of every serious agent shipping right now, and it is the shape Berrydesk gives you out of the box.
The 2026 model landscape, and why it matters before you write a line of code
Most agent tutorials you will read still default to one model for everything. That worked when GPT-4 was the only credible option. In 2026 it is a missed opportunity, both for cost and for capability.
The closed frontier
OpenAI's GPT-5.5 and GPT-5.5 Pro shipped in April 2026 with parallel reasoning - the model can pursue multiple solution paths simultaneously and pick the strongest. It is the safest default for general-purpose conversational reasoning and remains the most familiar API for teams coming from earlier OpenAI work.
Anthropic's Claude Opus 4.7 currently leads SWE-bench Pro at 64.3% and is, in our experience, the most reliable model for long, tool-heavy support workflows where one wrong action causes real customer pain. Both Claude Opus 4.6 and Sonnet 4.6 ship with a 1M-token context window at no surcharge, which is a quietly enormous shift in how agents can be designed - more on that below.
Google's Gemini 3.1 Ultra has a 2M-token context and is natively multimodal across text, image, audio, and video. Gemini 3.1 Pro leads GPQA Diamond at 94.3%, which translates in practice to strong domain reasoning when your support content covers technical or scientific products.
The open-weight frontier
The cost story for production agents has been rewritten by an open-weight wave that landed across April 2026:
- DeepSeek V4 (April 24, 2026) ships in two flavors - V4 Pro (1.6T parameters MoE, 49B active) and V4 Flash (284B / 13B active), both with 1M context. V4 Flash is priced at $0.14 per million input tokens and $0.28 per million output. For high-volume support traffic this is the kind of pricing where the cost per resolved ticket falls below a fraction of a cent.
- Moonshot Kimi K2.6 (April 21, 2026) is a 1T-parameter MoE built explicitly for agentic work. It can run 12-hour autonomous coding sessions, coordinate swarms of up to 300 sub-agents and 4,000 sequential steps, and ingests video natively. It scores 58.6 on SWE-Bench Pro. For agents that need to run long, branching workflows, this is the leader on the open side.
- Z.ai GLM-5.1 (April 7, 2026) is a 754B-parameter MoE under MIT license. It scores 58.4 on SWE-Bench Pro, ahead of GPT-5.4 (57.7) and Claude Opus 4.6 (57.3) on that benchmark, and it runs an 8-hour autonomous plan-execute-test-fix loop. Notably, it was trained entirely on Huawei Ascend 910B chips with no Nvidia in the stack, which is increasingly relevant to procurement conversations.
- Alibaba Qwen 3.6 offers a tiered family. The dense Qwen3.6-27B is Apache 2.0 and beats far larger MoE rivals on agentic coding benchmarks. Qwen3.6-35B-A3B is an open MoE with a strong local-deploy story. Qwen3.6-Plus and Qwen3.6-Max-Preview are proprietary and currently sit in the top six on coding benchmarks.
- MiniMax M2 / M2.7 (April 12, 2026) is a 230B / 10B-active MoE with open weights. Pricing is roughly 8% of Claude Sonnet at twice the speed. M2.7 hits 56.22% on SWE-Pro and 57.0% on Terminal Bench 2.
- Xiaomi MiMo-V2-Pro (March 18, 2026; weights open-sourced under MIT in April) crosses 1T total parameters with 42B active and a 1M context. The reasoning-first MiMo-V2-Flash (309B / 15B active) shipped in late 2025.
For a production support agent, the design question is no longer "which model do I use" but "which model do I use for what." A pragmatic Berrydesk deployment routes the long tail of routine traffic through DeepSeek V4 Flash or MiniMax M2 at near-zero unit cost, then escalates the genuinely hard tickets - angry customers, ambiguous policy questions, regulated domains - to Claude Opus 4.7, GPT-5.5 Pro, or Gemini 3.1 Ultra. That single design choice often cuts inference spend by 80%+ without any loss in resolution quality.
Why context windows changed the architecture
The other quiet revolution is the 1M–2M-token context window now standard at the frontier. Until recently, agent design assumed RAG was load-bearing - you had to chunk, embed, retrieve, and stuff snippets into a small context window or your agent would forget who it was. With Claude Sonnet 4.6 at 1M tokens, DeepSeek V4 at 1M, MiMo-V2-Pro at 1M, and Gemini 3.1 Ultra at 2M, an entire mid-sized knowledge base, full conversation history, and the company's policy library can sit in-context simultaneously. RAG becomes a tuning lever for cost and latency, not a hard requirement for correctness. Agents that struggled with cross-document reasoning ("does this refund policy apply to this customer's plan tier?") suddenly answer cleanly because the model can see both documents at once.
The skeleton of a working agent
If you are building from scratch, the smallest useful agent is a planner-executor loop that calls tools, observes results, and decides whether to continue. The Python sketch below uses a modern Anthropic SDK call with structured tool use, which is how serious 2026 agents are wired - JSON-coerced tool schemas, not regex-parsed action strings.
import os
from anthropic import Anthropic
import httpx
client = Anthropic() # reads ANTHROPIC_API_KEY from env
TOOLS = [
{
"name": "search_kb",
"description": "Search the company knowledge base for relevant docs.",
"input_schema": {
"type": "object",
"properties": {"query": {"type": "string"}},
"required": ["query"],
},
},
{
"name": "lookup_order",
"description": "Fetch order details for a customer by order ID.",
"input_schema": {
"type": "object",
"properties": {"order_id": {"type": "string"}},
"required": ["order_id"],
},
},
{
"name": "issue_refund",
"description": "Issue a refund for an order. Requires confirmation.",
"input_schema": {
"type": "object",
"properties": {
"order_id": {"type": "string"},
"amount_cents": {"type": "integer"},
"reason": {"type": "string"},
},
"required": ["order_id", "amount_cents", "reason"],
},
},
]
def search_kb(query: str) -> str:
# call your vector store / search API
return "..."
def lookup_order(order_id: str) -> dict:
return httpx.get(f"https://api.example.com/orders/{order_id}").json()
def issue_refund(order_id: str, amount_cents: int, reason: str) -> dict:
return httpx.post(
"https://api.example.com/refunds",
json={"order_id": order_id, "amount_cents": amount_cents, "reason": reason},
).json()
DISPATCH = {
"search_kb": lambda i: search_kb(i["query"]),
"lookup_order": lambda i: lookup_order(i["order_id"]),
"issue_refund": lambda i: issue_refund(**i),
}
def run_agent(user_message: str, system: str) -> str:
messages = [{"role": "user", "content": user_message}]
while True:
resp = client.messages.create(
model="claude-opus-4-7",
max_tokens=2048,
system=system,
tools=TOOLS,
messages=messages,
)
messages.append({"role": "assistant", "content": resp.content})
if resp.stop_reason != "tool_use":
return "".join(b.text for b in resp.content if b.type == "text")
tool_results = []
for block in resp.content:
if block.type == "tool_use":
result = DISPATCH[block.name](block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": str(result),
})
messages.append({"role": "user", "content": tool_results})
This is a deliberately small example, but the shape is the shape. Every Berrydesk agent - and every serious agent shipped on top of OpenAI, Anthropic, Google, or any of the open-weight providers - is doing some version of this loop with more guardrails. The interesting engineering happens in what surrounds it.
Memory: short-term, long-term, and what people get wrong
Memory is where most home-grown agents quietly fail in production. The naive approach - "stuff the whole conversation back in every turn" - works for the first ten messages and then starts to drift, lose track of important details, or simply burn money.
A working memory architecture has three layers:
- Working memory. The current conversation turn plus a small rolling window. With 1M-token context windows now standard, you can be much more generous here than older guides suggest. For most support agents, keeping the full conversation in-context is fine and dramatically reduces "agent forgot what I asked it" complaints.
- Episodic memory. Past conversations with this same customer, summarized rather than stored verbatim. A separate background job can produce these summaries - "this customer has had three refund requests, all approved, around shipping issues" - and inject them as system context.
- Semantic memory. The company knowledge base, product docs, policy library. This is where vector stores like Pinecone, Weaviate, pgvector, or Qdrant earn their keep. Even with huge context windows, retrieval is still the right tool when the corpus is bigger than what you want to send every turn.
A common pitfall is over-engineering this layer before you need it. Start with full-conversation working memory and a single retrieval call against your docs. Add episodic summaries when, and only when, you can point to specific customer pain caused by their absence.
Tools and AI Actions: where agents earn their keep
A model without tools is a chatbot. The leap to "agent" happens the first time the system actually changes the outside world - books a meeting, issues a refund, updates a CRM record, sends a Slack message.
Modern tool-use models - Claude Opus 4.7, GPT-5.5, Gemini 3.1, Kimi K2.6, GLM-5.1, Qwen3.6, MiMo-V2-Pro - are trained specifically to call structured tool schemas reliably, recover from errors, and chain multiple calls together. This was the part of agent design that most often broke in 2023–2024. In 2026 it is genuinely production-ready, but only if you respect a few rules:
- Make every tool idempotent or guarded. Refunds, payments, and outbound messages should never silently double-fire if the agent retries. Either the tool itself dedupes by request ID, or the orchestrator does.
- Validate inputs at the boundary. The model will occasionally produce a malformed argument. Pydantic or JSON Schema validation at the dispatch layer turns a hallucinated parameter into a recoverable error rather than a corrupted database row.
- Confirm destructive actions. For anything that moves money or sends an outbound message, design a two-step pattern - the agent proposes, the user confirms. The newest agentic models are reliable enough that this can feel like overkill, but the cost of a single wrong refund usually buys a lot of confirmation friction.
- Limit blast radius. A support agent does not need access to every internal API. Give it the smallest tool surface that covers the use case, and audit calls in production.
This is exactly the layer Berrydesk's AI Actions abstract - describe the action in natural language, point at an endpoint, set the auth, and the platform handles schema generation, validation, retries, and confirmation. If you are building from scratch, expect to write the same machinery yourself.
Setting up a development environment
If you do want to build from scratch, the 2026 starter kit has consolidated. Most teams converge on something close to this:
- Python 3.12+ (or Node 22+ if you prefer TypeScript). Verify with
python --version. - Virtual environment.
python -m venv .venv && source .venv/bin/activateon macOS/Linux, or.venv\Scripts\activateon Windows. - Core libraries.
pip install anthropic openai google-genai httpx pydantic python-dotenv. Addlangchainorllamaindexonly if you actually need their orchestration; for many agents, raw SDK calls are clearer. - API keys. Put them in a
.envfile at the project root, load withpython-dotenv. Never commit this file. Rotate keys if they ever land in a screenshot or a chat thread. - Vector store, if needed. Pinecone, Weaviate, Qdrant, or pgvector are all reasonable. For under a few million chunks, pgvector on the database you already operate is usually the lowest-friction choice.
- Observability. LangSmith, Helicone, Langfuse, and Phoenix all do roughly the same thing - capture every LLM call, every tool call, every prompt, and let you replay traces. Pick one before you write the agent, not after, because retrofitting tracing into a finished agent is much harder than starting with it.
Skip all of this if your goal is a customer support agent rather than a research project - Berrydesk gives you the same loop, the same tool surface, and the same observability with the four-step builder, and you can be live on a website, in Slack, in Discord, and on WhatsApp in about the time it takes to finish reading this post.
Advanced techniques worth knowing
Once you have the basic loop running, the upgrades that actually move metrics are surprisingly few:
- Routed model selection. Detect intent or difficulty cheaply, then send routine traffic to a fast, low-cost model (DeepSeek V4 Flash, MiniMax M2, Gemini 3.1 Flash) and reserve the frontier (Claude Opus 4.7, GPT-5.5 Pro) for escalations. This is the single highest-leverage change for cost.
- Plan-then-act prompting. Ask the model to write a short plan before it starts calling tools. Agentic models like Kimi K2.6 and GLM-5.1 are trained for this, and the plan also doubles as an audit log. For long workflows it is the difference between an agent that finishes the task and one that loops.
- Structured output for everything internal. When the agent is reasoning about its own state - picking a category, scoring a resolution, deciding whether to escalate - coerce JSON output with a schema. It eliminates an entire class of parsing bugs.
- Retrieval as a lever, not a default. With long-context models, you can often cut RAG out of the hot path entirely for the working set. Use it for the tail of the corpus or for the latency-sensitive cases where streaming through 800k tokens would feel slow.
- Self-critique passes. For high-stakes responses, have the model evaluate its own draft against a checklist before sending. This is cheap, surprisingly effective, and the agentic-tuned models do it well without much prompt engineering.
- Caching aggressively. Anthropic's prompt caching, OpenAI's automatic prefix cache, and equivalent features on Gemini and the open-weight providers can drop the marginal cost of long system prompts to near zero. If your agent has a 50k-token system prompt that doesn't change between turns, cache it.
Deployment: the parts nobody warns you about
Shipping an agent to production is its own skill. The model is the easy part. The hard parts:
Where it runs. Serverless platforms - AWS Lambda, Cloud Functions, Cloud Run, Vercel, Fly Machines - are usually the right starting point because cold-start cost is acceptable for chat workloads and scaling is automatic. Long-running agentic workflows (Kimi K2.6's 12-hour sessions, GLM-5.1's 8-hour loops) are different beasts and want a real worker queue plus durable state - Temporal, Inngest, or a homemade Postgres-backed job runner.
How it handles concurrency. A single chat session is sequential, but ten thousand concurrent chat sessions are not. Make sure the rate-limiting on your model provider matches your projected peak. Frontier providers will sell you higher tier limits; open-weight models running on dedicated infra (Together, Fireworks, Groq, DeepInfra) often have more flexible scaling.
On-prem and air-gapped. Regulated industries - healthcare, banking, defense, public sector - increasingly require this, and it is finally viable in 2026. MIT-licensed Chinese open weights like GLM-5.1, the open Qwen3.6 variants, MiMo-V2-Pro, and Apache-licensed alternatives let teams run a frontier-class agent entirely inside their own VPC with no data leaving the perimeter. This was a fantasy two years ago. It is a procurement checkbox now.
Monitoring. At minimum you want, per request: the user message, the agent's plan, every tool call and its result, the final response, total tokens, total cost, total latency, and whether the user marked it resolved. Wire this to a dashboard before you go live, not after a customer complains.
Feedback loops. Thumbs up/down at the message level, escalation rate, average turns per conversation, and tool-call success rate are the four metrics that actually predict whether the agent is improving. Track them weekly. The dashboard inside Berrydesk surfaces these by default; a from-scratch build needs you to instrument them yourself.
Scaling. Cache embeddings for the knowledge base. Cache repeated tool calls (order lookups, customer profiles) with a short TTL. Stream responses to the user as soon as the first tokens arrive - perceived latency drops by half even when actual latency does not.
Common pitfalls that kill agent projects
Across hundreds of Berrydesk deployments and many more in-the-wild agent projects, the same mistakes keep showing up:
- Building a generalist instead of a specialist. "Our agent will do anything" usually means "our agent does nothing well." Pick the three or four workflows that account for 60% of inbound volume and make those airtight before adding more.
- Skipping evals. If you cannot run the same fifty real customer messages through your agent before and after a change and see a measurable difference, you cannot improve it. Eval suites are unglamorous and the biggest single multiplier on agent quality.
- Treating the model like a database. Models hallucinate prices, SLAs, policy terms, and feature lists with confidence. Anything factual should come from a tool call against an authoritative source, not from the model's training data.
- Ignoring confirmation friction. Agents that issue refunds without explicit confirmation will, statistically, eventually issue a wrong refund. The blast radius matters more than the friction.
- Over-relying on one model. A multi-model strategy is not just cheaper, it is more resilient. When OpenAI has an outage, your agent should fall back to Claude or DeepSeek automatically.
- Forgetting humans. Even the best 2026 agent should hand off cleanly to a human for the small fraction of cases that need one. The handoff transcript matters as much as the agent's own response.
Build vs. buy: a quick honest take
If you are an engineering team at a company whose product is the agent - a vertical AI startup, a developer-tools company, a research lab - building from scratch makes sense, and this guide is for you.
If you are a support, success, or operations team at a company whose product is something else, the math almost never favors building. A platform like Berrydesk gives you model choice (GPT-5.5, Claude Opus 4.7, Gemini 3.1, DeepSeek V4, GLM-5.1, Kimi K2.6, Qwen3.6, MiniMax M2, and more), training on docs, websites, Notion, Google Drive, and YouTube, branded chat widgets, AI Actions for bookings and payments, and deployment to web, Slack, Discord, and WhatsApp - all of which would take a small team a quarter or two to recreate, and a year or two to harden.
The right question is not "can we build this." It is "is the marginal value of building it ourselves greater than the engineering quarters it will cost." For most support orgs, the answer is no.
Where this is going
Three trends are worth watching as 2026 unfolds:
- Multi-agent coordination. Kimi K2.6's 300-sub-agent swarms and Claude Opus 4.7's improved sub-agent patterns are the early shape of what serious agentic systems will look like - a planner agent dispatching specialist agents that each own a narrow tool surface. Expect this to become standard for any workflow longer than a few minutes.
- Long-running autonomous sessions. GLM-5.1's 8-hour and Kimi K2.6's 12-hour autonomous loops imply a different programming model - one where the agent persists state across hours or days, resumes from interruptions, and reports back. The orchestration layer for this is still settling.
- On-prem frontier. Open-weight Chinese models with permissive licenses are reshaping what regulated industries can deploy. Expect the next wave of healthcare, banking, and government agent projects to default to GLM-5.1, Qwen3.6, or MiMo-V2-Pro running inside the customer's own perimeter, with the closed frontier reserved for the explicitly non-sensitive workloads.
The throughline is simple: the agent stack is consolidating, the unit economics are collapsing, and the engineering bar to ship something useful is lower than it has ever been.
If you want to see what a production-ready agent looks like without writing the loop yourself, start a free Berrydesk agent. Pick a model, point it at your docs, wire your AI Actions, and ship to your channels. The frontier is genuinely accessible now - the only question is what you build with it.
Ship a production AI support agent without the boilerplate
- Pick from GPT-5.5, Claude Opus 4.7, Gemini 3.1, DeepSeek V4, GLM-5.1, Kimi K2.6, Qwen3.6, MiniMax M2 and more
- Train on your docs, sites, Notion, Drive, and YouTube - wire AI Actions for bookings, refunds, payments
Set up in minutes

Chirag Asarpota is the founder of Strawberry Labs, the team behind Berrydesk - the AI agent platform that helps businesses deploy intelligent customer support, sales and operations agents across web, WhatsApp, Slack, Instagram, Discord and more. Chirag writes about agentic AI, frontier model selection, retrieval and 1M-token context strategy, AI Actions, and the engineering it takes to ship production-grade conversational AI that customers actually trust.


